Moin,
in Wittenberg, hat mir jemand der Anwesenden (leider habe ich den Namen vergessen, weil ich zu sehr mit eigentlichen Problem beschäftigt war - Sorry)
in meinem Projekt nicht nur GIT eingerichtet, sondern mir auch gezeigt, was ich nach einer Änderung machen muss.
Leider gibt es genau von der Aktion keinen Video-Mitschnitt und das ging alles so schnell, das es mir zu Hause nicht gelungen ist, das alles nachzuvollziehen.
Kann mir da noch mal jemand unter die Arme greifen?
Gruß Heiko
GIT für Lazarus-Projekte
-
kralle

- Lazarusforum e. V.
- Beiträge: 1383
- Registriert: Mi 17. Mär 2010, 14:50
- OS, Lazarus, FPC: Manjaro Linux, Mint und Windows 10 ,Lazarus 4.99, FPC-Version: 3.3.1
- CPU-Target: 64Bit
- Wohnort: Bremerhaven
- Kontaktdaten:
GIT für Lazarus-Projekte
OS: MX Linux, Linux Mint und Windows 11
FPC-Version: 3.3.1 , Lazarus 3.99
+ Delphi XE7SP1
FPC-Version: 3.3.1 , Lazarus 3.99
+ Delphi XE7SP1
Re: GIT für Lazarus-Projekte
würde mich auch sehr interessieren
-
fliegermichl

- Lazarusforum e. V.
- Beiträge: 1805
- Registriert: Do 9. Jun 2011, 09:42
- OS, Lazarus, FPC: Lazarus Fixes FPC Stable
- CPU-Target: 32/64Bit
- Wohnort: Echzell
Re: GIT für Lazarus-Projekte
Wenn du etwas fertig gemacht hast und sichern willst
Code: Alles auswählen
git commit -a -s -m"Hinweise was ich hier getrieben habe"
// Wenn es ein Remote Repository gibt wo ich den Kram hin sichere dann jetzt noch ein
git push origin master
// Ich richte mir normalerweise ein default Remote Repository ein. Da macht man einmal:
git push origin master --set-upstream
// danach reicht
git push
-
kralle
- Lazarusforum e. V.
- Beiträge: 1383
- Registriert: Mi 17. Mär 2010, 14:50
- OS, Lazarus, FPC: Manjaro Linux, Mint und Windows 10 ,Lazarus 4.99, FPC-Version: 3.3.1
- CPU-Target: 64Bit
- Wohnort: Bremerhaven
- Kontaktdaten:
Re: GIT für Lazarus-Projekte
Moin,
Gruß Heiko
P.S. Wenn ich ein NAS habe auf dem ich aber keine Software installieren kann (also nur eine Festplatte im Netzwerk), könnte ich trotzdem mit mehreren Rechnern abwechselt arbeiten und gemeinsam die Versionsverwaltung nutzen?
Ich glaube mir und auch dem Mitfragenden, wäre eine StepByStep Anleitung, die wir vielleicht auch in der Wissensdatenbank parken können , sehr angenehm.fliegermichl hat geschrieben:Wenn du etwas fertig gemacht hast und sichern willst
Wenn ich das richtig verstehe, ist das hier Schritt 3.Code: Alles auswählen
git commit -a -s -m"Hinweise was ich hier getrieben habe"
Also, nachdem ich GIT eingerichtet habe und nachdem ich die erste Version erstellt habe und dann eine Änderung gemacht habe. Richtig?Also, wenn ich das was ich in Schritt 3 erzeuge z.B. noch mal zusätzlich auf einem NAS sichern will - oder?Code: Alles auswählen
// Wenn es ein Remote Repository gibt wo ich den Kram hin sichere dann jetzt noch ein git push origin masterHmm, das erschliesst sich mir jetzt nicht so.Code: Alles auswählen
// Ich richte mir normalerweise ein default Remote Repository ein. Da macht man einmal: git push origin master --set-upstream
Ich muß doch das Repo in jedem Projekt erzeugen oder nicht?hmmm.Code: Alles auswählen
// danach reicht git push
Gruß Heiko
P.S. Wenn ich ein NAS habe auf dem ich aber keine Software installieren kann (also nur eine Festplatte im Netzwerk), könnte ich trotzdem mit mehreren Rechnern abwechselt arbeiten und gemeinsam die Versionsverwaltung nutzen?
OS: MX Linux, Linux Mint und Windows 11
FPC-Version: 3.3.1 , Lazarus 3.99
+ Delphi XE7SP1
FPC-Version: 3.3.1 , Lazarus 3.99
+ Delphi XE7SP1
-
Socke
- Lazarusforum e. V.
- Beiträge: 3193
- Registriert: Di 22. Jul 2008, 19:27
- OS, Lazarus, FPC: Lazarus: SVN; FPC: svn; Win 10/Linux/Raspbian/openSUSE
- CPU-Target: 32bit x86 armhf
- Wohnort: Köln
- Kontaktdaten:
Re: GIT für Lazarus-Projekte
Für Lazarus-Projekte kann ich diese .gitignore-Datei empfehlen. Speichert diese in eueren Projektverzeichnisse um typische von Free Pascal erzeugte Dateien von eurer Versionierung auszunehmen.
Ja. Du erstellst auf der Netzwerkfestplatte ein "bare"-Repository (d.h. ohne lokales Arbeitsverzeichnis, in dem du die Dateien direkt bearbeiten könntest). Dorthin sendest du deine Änderungen von allen Rechner und kannst andere Änderungen von dort beziehen.kralle hat geschrieben:P.S. Wenn ich ein NAS habe auf dem ich aber keine Software installieren kann (also nur eine Festplatte im Netzwerk), könnte ich trotzdem mit mehreren Rechnern abwechselt arbeiten und gemeinsam die Versionsverwaltung nutzen?
MfG Socke
Ein Gedicht braucht keinen Reim//Ich pack’ hier trotzdem einen rein
Ein Gedicht braucht keinen Reim//Ich pack’ hier trotzdem einen rein
-
Warf
- Beiträge: 2316
- Registriert: Di 23. Sep 2014, 17:46
- OS, Lazarus, FPC: Win10 | Linux
- CPU-Target: x86_64
Re: GIT für Lazarus-Projekte
Mir war grad Langweilig, also hab ich mal ein bisschen was zusammengeschrieben:
Hier ist mal eine etwas erweiterte Erklärung für Git, denn mMn. kann man Git nicht richtig verwenden wenn man es nicht richtig verstanden hat und im gegensatz zu SVN ist Git deutlich komplizierter. Das sollte einen aber nicht Abschrecken, denn wenn mans einmal verstanden hat ist alles ganz einfach. Außerdem hat Git die Versionskontrollkriege gewonnen, also ob mans mag oder nicht, drum rum kommt man eh kaum.
Git basiert auf einem Graphen. Die Knoten des Graphen sind so genannte Commits. Diese bezeichnen Momentaufnahmen (Snapshots) des aktuellen Code Status und bestehen im wesentlichen aus drei Dingen:
1. Allen Vorgänger-Commits auf denen es aufbaut, welche die Kanten im Graphen darstellen
2. Meta Informationen, wer den Commit verfasst hat (Name, E-Mail), wann der Commit getätigt wurde sowie eine kleine Nachricht (Message) was der Commit denn macht
3. Die Code Änderungen zu den Vorgängern
Über diese 3 Sachen wird dann ein Hash gebildet, über den jeder Commit eindeutig identifiziert werden kann.
Ein kleines Beispiel, ich arbeite an einem Git Projekt und habe grade eine Funktion hinzugefügt. Dann würde ich einen neuen Commit erstellen, welcher diese Funktion enthält, eine Message wie "Adding Function XXX" zusammen mit meinem Namen, den aktuellen Datum und einer Referenz was die Version war mit der ich angefangen habe.
Die Commits die sich gegenseitig Verlinken (da jeder Commit einen Verweis auf den vorrigen Commit enthält) bilden damit den oben erwähnten Graphen. Ein Git repository speichert nun diesen Graphen und stellt eine akutelle Arbeitsversion, den Working Tree, bereit. Der Working Tree basiert dabei auf einem Commit, der wird HEAD genannt, also der aktuelle Commit den wir betrachten. Wenn wir einen neuen Commit hinzufügen, wird der aktuelle HEAD als Vorgänger in dem Commit vermerkt.
Während Git zwar jeden Commit einzeln über einen Hash addressieren kann, arbeitet man für gewöhnlich auf so genannten Branchen. Ein Branch ist eine Serie an Commits der man praktisch einen Namen gibt. Der Branch selbst bezeichnet dann praktisch den letzen Commit in der Serie. Der Standard-Branch ist der "master" Branch, den es in jedem Repository gibt.
Doch mal zum praktischen Teil. Wenn man Git installiert hat (https://git-scm.com/), kann man das git programm einfach über die Kommandozeile bedienen (für Windows wird eine eigene "Git-Bash" mitgeliefert, die die grundlegenden Unix-Shell funktionen zur Verfügung stellt). Sagen wir mal wir haben ein Projekt in einem Ordner, so müssen wir erst mal ein Git Repository dafür in diesem Ordner erstellen. Dafür navigieren wir unsere Shell in den Projektordner und rufen "git init" auf:
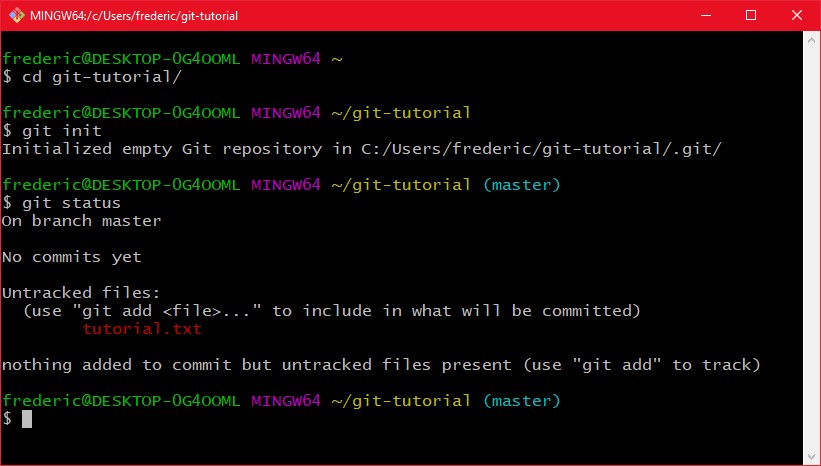
Das Kommando "git status" berichtet über den aktuellen Status des Git repositories. In dem Bild oben können wir sehen, dass zunächst einmal der master Branch erzeugt wurde, dieser branch aber noch keinen Commit enthält. Außerdem sagt git uns das es die Datei tutorial.txt, an der ich grade schreibe, in dem Ordner gibt, allerdings diese nicht im git repository hinzugefügt ist, also "untracked" (Änderungen werden nicht verfolgt) ist. Das wollen wir schnell mal ändern, und fügen einen ersten Commit hinzu, mit dem Inhalt den ich bis jetzt geschrieben habe.
Dafür müssen wir git zunächst einmal sagen welche dateien wir denn Commiten wollen. Das geht über "git add Dateiname1 [Dateiname2 [...]]" (für die Leute die ungewohnt mit der typischen schreibweise für Kommandozeilen Manuals sind, was in "[" und "]" steht ist optional, oben das bedeutet also das man beliebig viele Dateinamen angeben kann). Wenn man alle Dateien hinzufügen möchte die als untracked gekennzeichnet sind (im git status), kann man einfach "git add -A" verwenden. In meinem Fall führe ich also jetzt "git add tutorial.txt" aus:
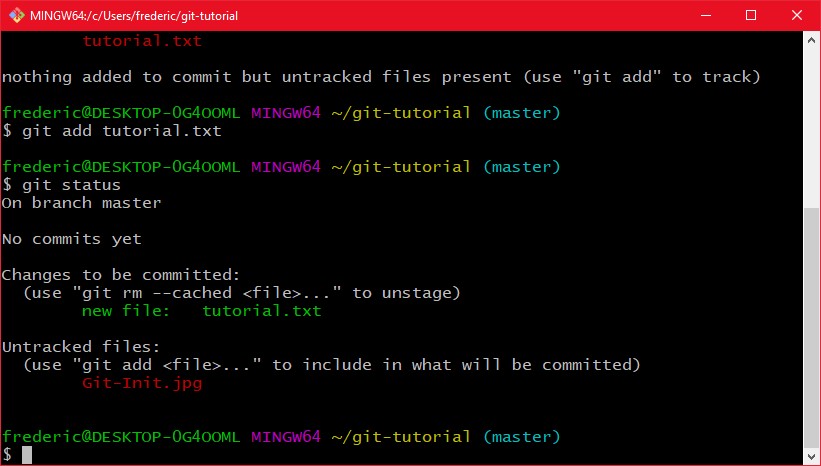
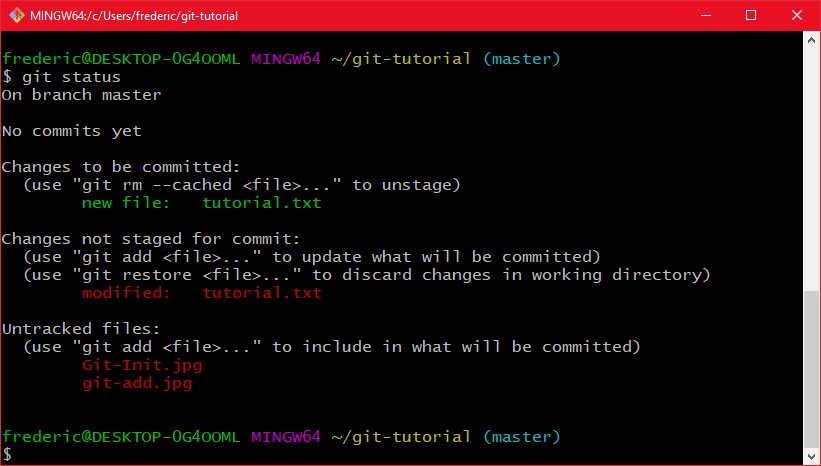
Das "git status" sagt uns nun das eine änderung zum Commit vorgemerkt wurde, die erstellung der datei tutorial.txt (außerdem erkennt git den Screenshot von oben als neue Datei, den will ich aber nicht commiten). Diese vorgemerkten Änderungen nennt man stage. Das wichtige dabei ist, es wird die Datei so vorgemerkt wie zu dem Zeitpunkt des "git add". Die Änderungen die ich seit dem gemacht hab sind da nicht drin, wie ein weiteres "git status" nach ein paar Änderungen zeigt:
Der nächste Schritt ist das Erstellen des eigentlichen commits. Doch bevor wir commiten können, müssen wir git erst einmal sagen wer wir sind. Das geht via "git config".
Das --global setzt diese Einstellung für den Benutzer dieses PC's, wenn man es weg lässt wird es nur für dieses Repositroy gesetzt (z.B. wenn man eine Firmenmail hat und eine Private Mail).
Nachdem wir git gesagt haben wer wir sind, können wir nun mit "git commit" commiten. Wenn man git commit ohne weitere Argumente aufruft, öffnet sich der für Git eingestellte Editor (Vim oder Nano standardmäßig) um eine Commit Nachricht einzutragen:
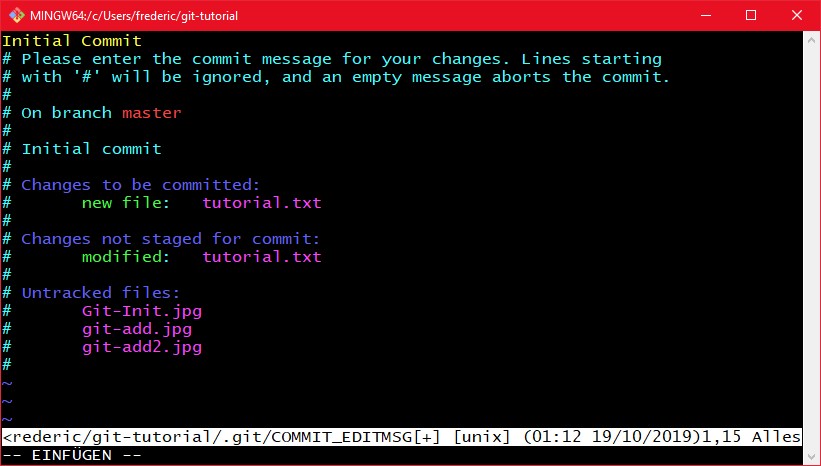
Als Nachricht habe ich "Initial Commit" gewählt, da das die standardmäßige Nachricht ist die bekannte Git plattformen wie GitHub oder GitLab für neue repositories immer wählen. Zeilen die mit einem "#" anfangen sind auskommentiert, und werden nicht als Commit Message betrachtet. Diese geben nochmal grundlegend die Zusammenfassung die einem git status anzeigt. Dann speichert und schließt man den Editor einfach. Wenn man den Commit abbrechen will, schreibt man einfach nichts rein (also eine Leere Commit Message/nur kommentare drin) und speichert und schließt den Editor (z.B. wenn man bei der Zusammenfassung in den Kommentaren merkt das man was commited was eigentlich nicht commited werden soll, wie Debug Code).
Der "git commit" Befehl kann noch einige Argumente nehmen. "git commit -a" z.B. staged automatisch alle modifikationen in getrackted files (also alles was im "git status" unter "changes not staged for commit" fällt, nicht die "untracked files") vor dem Commit, kann also alle Änderungen gleich mit commiten, ohne das man ein "git add" vorher machen muss. Außerdem gibt es noch die -m Option, mit der man direkt die Commit Message übergeben kann, also z.B. "git commit -m "Initial Commit". Davon würde ich aber strikt abraten aus zwei Gründen. Zum einen fehlt einem die Übersicht im Commit Editor (über was commited wird, was untracked ist, etc.), sowie die möglichkeit abzubrechen, wenn man das nicht Commiten möchte. Grade zusammen mit der -a Option, kann es sehr leicht passieren das man außversehen Debug Code o.ä. mit Commited den man eigentlich draußen lassen würde, und ein schnelles drüberschauen über die Kommentare im Editor kann einem aufwändiges zurücksetzen im Nachinein ersparen. Zum anderen haben Plattformen wie GitHub oder GitLab syntaktische hervorhebung für Code über "``". D.h. wenn man einen Ausdruck als Code markieren will, setzt man den in ``, z.B. wenn man eine Funktion hinzufügt könnte die Message so aussehen: "Adding Function `FunctionThatDoesSomeStuff`", um klarzustellen das der Funktionsnamen im Source FunctionThatDoesSomeStuff ist. Das Problem ist nun das `` in Bash einen Befehl kennzeichnen der Ausgeführt werden soll. Wenn man also z.b. sowas schreibt: git commit -m "Adding description for `rm -rf /`" hat man schwup die wupp sein gesammtes Linux system gelöscht, da die Bash dumm wie sie ist, einfach "rm -rf /" ausführt. Daher empfehle ich nicht -m zu benutzen.
Jetzt nach meinem Commit habe ich ein gutes Stück weiter an diesem Tutorial gearbeitet, und würde gerne die neuen Änderungen commiten. Das geht jetzt ganz einfach über "git commit -a" wie oben beschrieben. Nun möchte ich meine bisherigen 2 Commits sehen. Dafür gibt es den Befehl "git log" (da ich nicht möchte das irgendwer der diesen Beitrag findet mir einfach so Mails schickt habe ich meine E-Mail addresse zensiert):
Das log zeigt die Commits, sortiert nach der Reihenfolge im Graphen, mit der Message, Datum, Committer Name und E-Mail, sowie eindeutigem Hash an. Außerdem markiert uns git log noch welche Branches auf welche Commits zeigen. In meinem Fall ist master = HEAD und sie zeigen auf den neusten Commit den ich grade gemacht hab.
Jetzt möchte ich aber bevor ich commite sehen was genau commited wird. Dafür gibt es "git diff". Ohne weitere Argumente zeigt "git diff" die Anderungen an den getrackten Dateien gegen HEAD an. In meinem Fall also alles was ich an der tutorial.txt seit dem Letzten commit geändert habe:
Das rote sind die Zeilen die gelöscht wurden, das grüne die Zeilen die hinzugefügt wurden, und das graue die Zeilen die gleich geblieben sind. Das diff basiert dabei auf Zeilenbasis, eine änderung in einem Wort, führt also dazu das diese Zeile in der alten Fassung gelöscht wurde (also rot erscheint) und in der neuen Fassung direkt drunter hinzugefügt wurde (also in grün).
Ich kann mir aber auch die unterschiede zu einzelnen Commits anzeigen lassen "git log 2ef5dba7c" zeigt mir z.B. die unterschiede zwischen meiner akutellen Arbeitskopie und dem Initialen Commit 2ef5dba7ca056e1803aa492b23aed060ab8777a4 (kann für die Befehle abgekürzt werden auf die ersten paar zeichen des Hashs) an. Die Unterschiede zwischen zwei Commits lassen sich via "git diff commitID1 commitID2" anzeigen lassen, wobei das git diff die änderungen von Commit1 zu Commit2 anzeigt (wenn man also die beiden vertauscht ist das was vorher rot war grün und anders rum, da die änderungen praktisch dann die Rückgänigmachung wären).
Man kann Commits auch relativ zu anderen Commits identifizieren. Dafür kann man über ~ in der Historie zurückgehen. "02501047d9~1" bezeichnet damit den ersten commit vor "02501047d9". "git diff 02501047d9~1 02501047d9" zeigt also die unterschiede an die der Commit 02501047d9 hinzugefügt hat (also die unterschiede Zwischen dem Initial Commit und dem zweiten Commit). Außerdem können Commits auch über Branch Namen angesprochen werden. "git diff HEAD~2" gibt mir also die änderungen der letzten 2 commits zurück.
Nun, da wir wissen wie wir Commits erstellen, uns die Historie anschauen und Änderungen im Detail betrachten können, kommen wir zu den etwas komplexeren Themen. Sagen wir mal wir haben in unserer Software einen Bug festgestellt der vorher noch nicht da war, und wollen feststellen wann dieser dazu kam, du möchtest also zurück zu einer älteren Version gehen. Das geht über "git checkout" Wenn wir unser Repository als Graph betrachten, so ist unser aktuelles Arbeitsverzeichnis eine Instanz einer Commits. Der Commit den wir uns aktuell betrachten wird über den HEAD markiert. Wenn wir jetzt also ein "git checkout" machen wird der HEAD auf einen anderen Commit gesetzt, und damit dieser Commit in unser Arbeitsverzeichnis geschrieben. Für dieses Beispiel checken wir doch einfach mal den "Initial Commit" aus
Zunächst einmal gibt uns Git hier ne ganze Menge text. Der Grund dafür ist, das nun unser HEAD auf einen Commit zeigt, und nicht mehr Teil eines Branches ist. Der Commit liegt zwar auf dem "master" branch, aber wir sind dennoch jetzt im detached HEAD mode, was heißt, das jeder Commit den wir jetzt machen würden, zu keinem Branch hinzugefügt werden würde. Wenn wir also was anderes auschecken, gibt es keinen Branch, und damit keinen Namen, mit dem wir den Commit wieder finden würden, und damit ist dieser Commit verloren. Wir haben keine Möglichkeit den wieder zu finden, daher sagt uns diese Nachricht wie wir in solchen Fällen agieren können.
Die letzte Zeile, die ich markiert habe, sagt uns nun das wir den Commit 2ef5dba Initial Commit wiederhergestellt haben, und unser Arbeitsverzeichnis in dem Zustand dieses Commits ist. Jetzt könnten wir z.B. unsere Anwendung testen, ob der Bug immernoch vorkommt. Und wenn wir damit fertig sind, und auf dem "master" Branch weiterarbeiten wollen, müssen wir den wieder Auschecken mittels "git checkout master".
Wenn man nur einzelne Dateien zurücksetzen möchte, geht das über "git checkout -- PFADE". z.B. "git checkout HEAD~1 -- tutorial.txt" würde die tutorial.txt auf die version vor dem letzten Commit zurücksetzen. Das ist oft Hilfreich wenn man änderungen die man gemacht hat verwefen will, einfach "git checkout HEAD -- pfad/zu/einer/Datei" eintippen und die Datei pfad/zu/einer/Datei wird dann wieder auf den Zustand des letzten Commits zurückgesetzt.
Es kommt öfter als man möchte vor, das man etwas commited hat was man nicht möchte, oder einfach einen Commit komplett löschen will. Dafür gibt es den befehl "git reset COMMIT". Dieser setzt den aktuellen Branch auf einen neuen Commit. Man unterscheidet hierbei zwischen Soft- und Hard-Reset. Bei einem Soft Reset wird der Commit zwar vom Branch entfernt, aber die Änderungen bleiben lokal erhalten. Sagen wir mal du hast eine Datei commited die du eigentlich nicht drin haben willst und merkst das erst nach dem Commit z.B. habe ich jetzt die Git-Init.jpg commited und sehe das dann an der Nachricht beim git commit. Dann kann ich einfach mittels soft reset das ganze zurücksetzen und nochmal neu, richtig commiten, ohne irgendwelche daten zu verlieren:
Der Hard Reset resettet auch das Arbeitsverzeichnis, und löscht die Änderungen damit permanent. Damit sollte man sehr vorsichtig sein. Den macht man mit "git reset --hard COMMIT".
Es kommt öfter mal vor das man vor einem "git checkout" oder "git reset" bereits einige änderungen an seinem Code gemacht hat, die aber noch nicht soweit sind das man einen eigenen Commit dafür machen will. Um solche änderungen zwischen zu speichern, bevor man eventuell größere Änderungen an dem Repository vornimmt, kann man diese änderungen im stash zwischenspeichern. Der stash ist ein Stack von Arbeitsänderungen. Ich kann auf den stash pushen, mit "git stash push" oder kurz "git stash", und den letzten Stash mit "git stash pop" wiederherstellen. Wenn ich also jetzt in der Commit historie zurückgehen will, ohne einen neuen commit zu machen, würde ich meine änderungen zu erst Stashen, dann den checkout machen, und dann wieder unstashen:
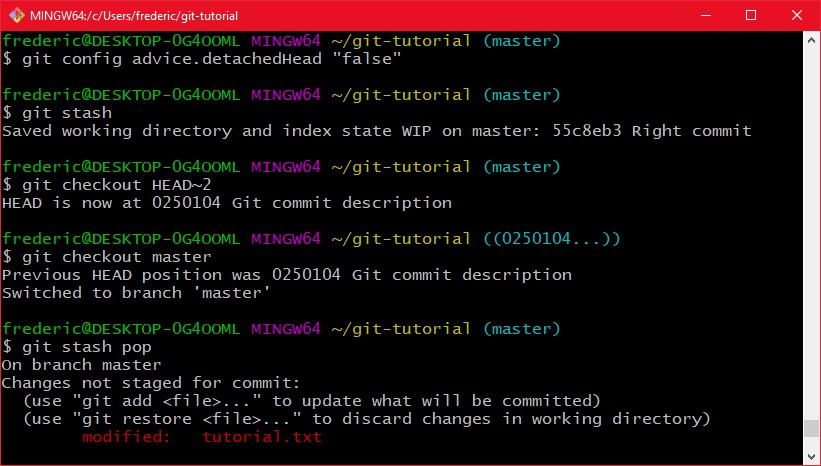
Eine weitere schöne eigenschaft von git stash ist, wenn ich z.B. grade ein Feature entwickle und plötzlich ein Bug auftritt, kann ich meine änderungen einfach stashen, schauen ob sie durch die aktuellen Änderungen kamen und wenn ja, kann ich den stash wieder popen und die Fehlerquelle suchen. Mit -- kann man auch einfach einzelne Dateien stashen:
Damit wären so die grundlegenden Basics der git Versionskontrolle abgedeckt, kommen wir zu etwas komplexeren Dingen. Wie bereits erwähnt gibt es Branches, die praktisch eine reihe an Commits bezeichnen. Branches haben mehrere Gründe. Zum einen wird Git Plattformen wie GitHub oft zum veröffentlichen von Software verwendet. Dabei will man dann sicherstellen das der master branch immer eine halbwegs stabile version ist, bzw. zumindest sollte der master branch immer Kompilieren. Wenn man ein solches Projekt am laufen hat und ein neues Feature entwickeln will, möchte man trozdem seine Arbeit auf dem Server sichern. Um den master Branch stabil zu halten, sollte man daher auf einem neuen Branch arbeiten. Ein anderer Einsatzweck für Branches ist wenn man mit mehreren Leuten an einem Projekt arbeiten, möchte man nicht unbedingt immer jede Änderung von jedem Teammitglied immer synchronisieren müssen. Dafür kann jedes Teammitglied einen eigenen Branch für seine Zwecke erzeugen, dieser basiert dann auf dem neusten master commit zu der Zeit zu der der Branch erzeugt wurde und somit arbeitet jeder für sich, und am ende müssen dann nur einmal alle Branches synchronisiert (gemerged) werden.
Um einen branch zu erzeugen kann man "git checkout -b branchName" verwenden, das erzeugt einen Branch und wechselt direkt zu diesem. Sagen wir mal ich hätte jetzt einen Korrekturleser, der dieses Tutorial gegen ließt und einige rechtschreibfehler korrigieren möchte:
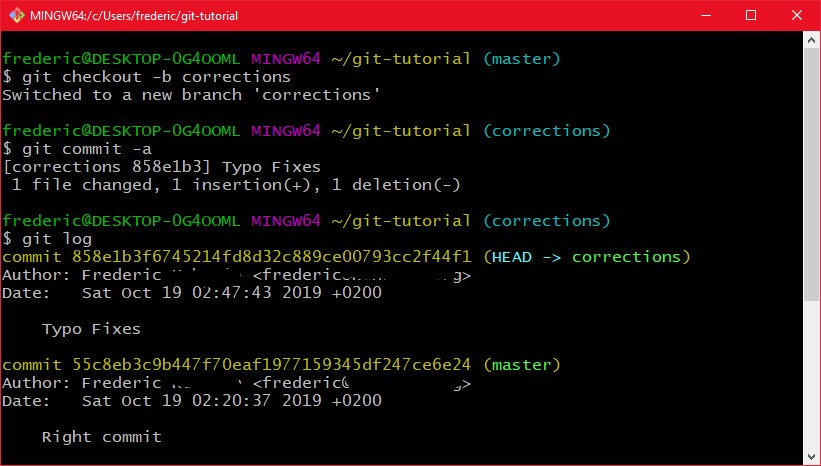
Hier wird ein neuer Branch corrections erstellt, auf dem dann ein neuer Commit mit Typo Fixes erstellt wird. Im git Log ist dann zu sehen das sich dieser branch um einen Commit von master unterscheidet.
Wenn ich nun diese Änderungen auf master übernehmen will mache ich einen so genannten merge, mit "git merge":
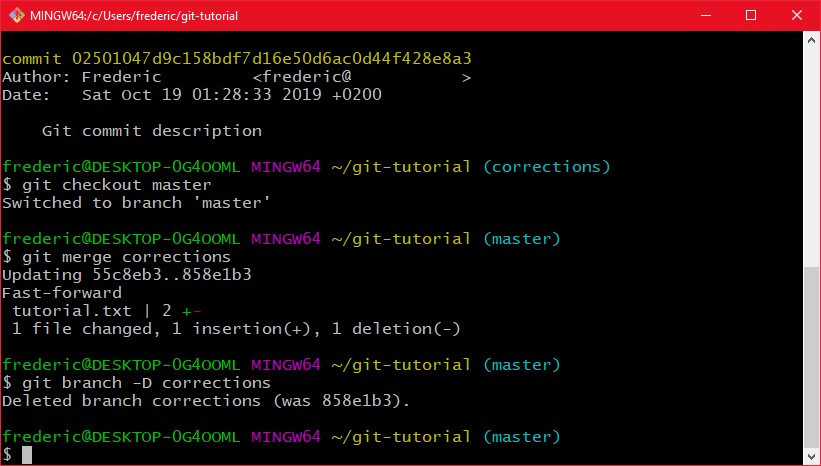
Dafür gehe ich zu erst wieder auf den master branch (in den ich ja reinmergen möchte), und sage dann "git merge corrections". Jetzt übernimmt git automatisch die Änderungen vom branch corrections und wendet sie auf master an. Den branch corrections kann ich dann nach dem merge mittels "git branch -D corrections" löschen.
Wenn es bei einem Merge zu einem Konflikt kommt, z.B. wurde auf dem master branch weiteres bearbeitet, wovon corrections nichts weiß, so versucht git diese beim merge automatisch aufzulösen. Wenn das schief geht muss man das per hand machen. Das geht aber für dieses Tutorial zu weit, da dieses Tutorial vorerst nur an Leute gerichtet ist die alleine git verwenden und das eher ein Team problem ist.
Wenn man mehrere Branches hat, kann man die sachen die oben mit commits gemacht wurden natürlich auch mit branches machen. So kann man z.B. master auf den aktuellen commit von corrections setzen via "git reset [--hard] corrections".
Zum Schluss möchte ich noch kurz auf Online Repositories zu sprechen kommen. Ob man nun git verwendet um seinen Code auf GitHub o.ä. zu veröffentlichen, oder einfach ein online Backup haben möchte, so muss man sein git Repository mit einem Online Repository, einem so genannten Remote, verbinden.
Wenn man z.B. auf GitHub ein Repository hat, ein frisch erstelltes, oder ein bereits bestehendes, so findet man (meist irgendwo oben auf der Startseite des Repos) eine "clone URL". Diese gibt es für SSH oder HTTPS, zwei protokolle die git kann. Auf die beiden Methoden werde ich später nochmal genauer eingehen. Zunächst einmal arbeiten wir aber mit der HTTPS URL.
Gehen wir jetzt erst mal von dem Fall aus das wir unser Repository auf GitHub hochladen wollen. Dann erstellen wir zunächst einmal ein Leeres Repository auf GitHub (wichtig, weder ReadMe noch gitignore erzeugen lassen)
Da sehen wir dann auch schon kurze Erklärung wie es weiter geht. Oben finden wir unsere clone URL https://github.com/Nutzername/ReposName.git. Nun fügen wir diese als remote zu unserem repository hinzu via "git remote add origin URL". Damit können wir jetzt immer origin statt der URL schreiben.
Nun müssen wir unseren master branch nur noch auf den server hochladen. Um das Lokale repository auf den server hochzuladen gibt es das Kommando "git push". Bei der ersten benutzung müssen wir git aber noch sagen welcher remote branch dem aktuellen branch entsprechen soll, wir müssen also in git sprech den lokalen branch einen remote branch tracken lassen.
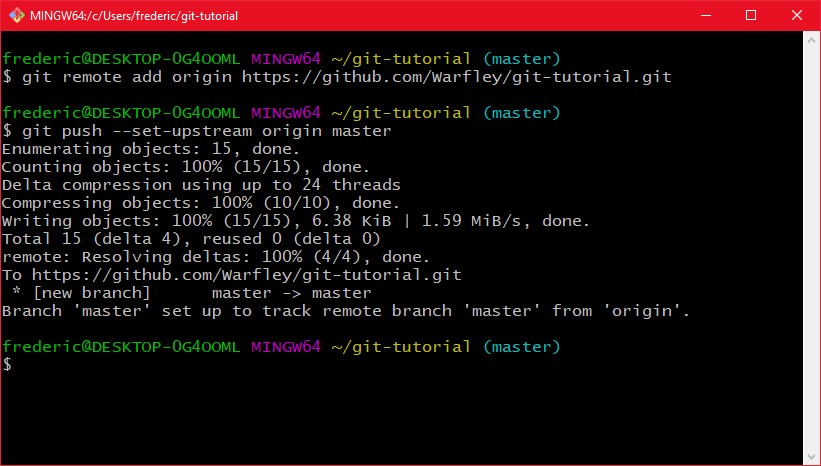
Der push befehl gibt uns dann ein bisschen was an Text zurück, über den Status des Hochladens. Da wir HTTPS benutzen werden wir bei jedem Push nach einem Passwort gefragt, das müssen wir dann eingeben.
Die letzte Zeile in der push ausgabe sagt uns dann das der branch master nun origin master folgt (trackt) und damit benötigen wir für folgende pushs jetzt nicht mehr das "--set-upstream ..." Wenn wir jetzt lokal weiter gearbeitet haben, ein paar commits gemacht haben, und die am ende des Tages zum Backup hochladen wollen, machen wir nur noch ein "git push" und alles ist synchronisiert
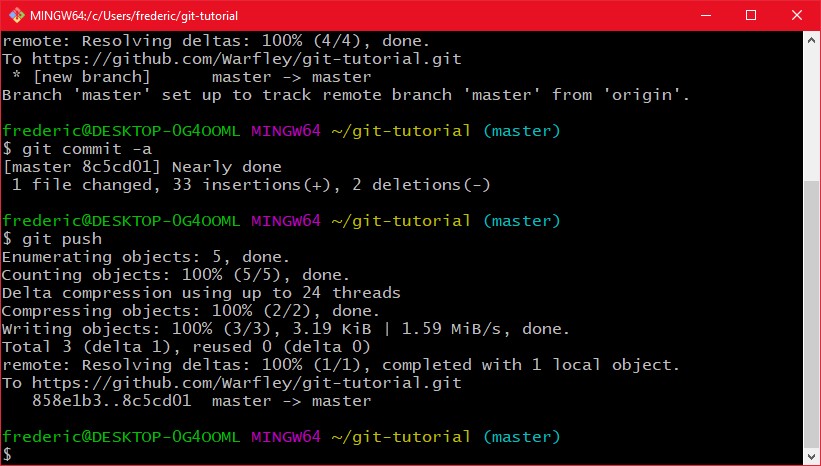
Wenn man GitLab benutzt muss man nicht vorher ein Repo erstellen, "git push --set-upstream URL master" erzeugt automatisch ein repository mit dem Namen der in der URL angegeben wird, solang die URL die typische GitLab URL form hat.
Wenn wir nun auf einem Zweiten rechner das git Repository runterladen wollen, können wir das über "git clone URL [ordner]" machen. Wenn ein (Ziel-)Ordner angegeben wird, dann wird der Ordner mit diesem Namen erstellt und da rein geklont, ansonsten wird ein neuer Ordner mit dem Namen des Repositories erstellt. Das git clone erzeugt direkt den lokalen master branch und trackt den gegen origin/master.
Die serverseitigen sachen werden praktisch als eigene Branches von git gehandhabt. Der Branch "master" der im online repo origin liegt, wird mit origin/master addressiert. Wenn du also die Änderungen deines Lokalen branches mit dem Server vergleichen willst kannst du das via "git diff origin/master" machen:
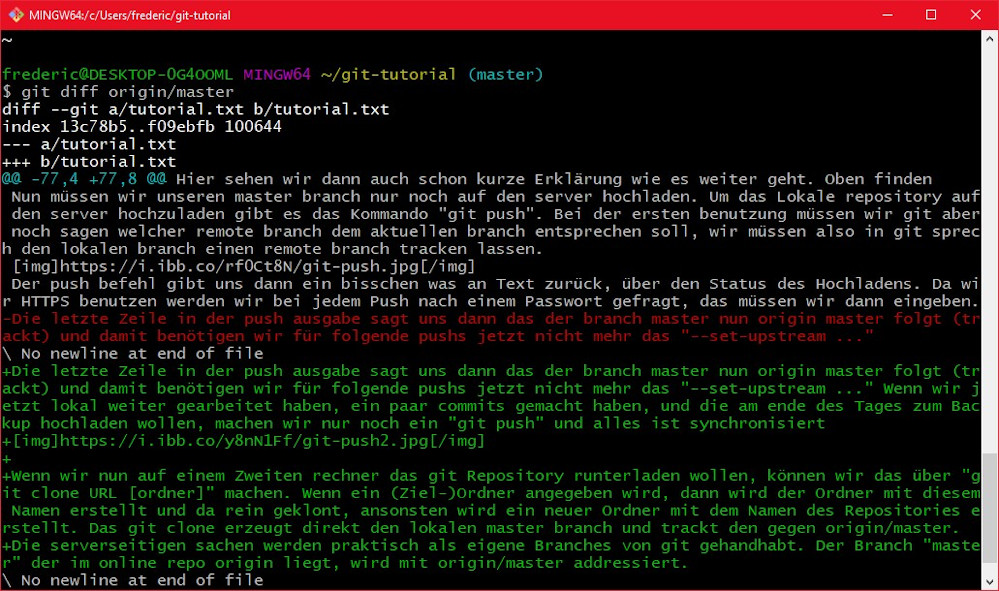
Generell kannst du origin/branch genauso verwenden wie Commit Hashs, nicht wie branches. D.h. wenn du z.b. "git checkout origin/master" machst landest du wieder im detached HEAD mode, und befindest dich praktisch auf keinem branch.
Wenn du jetzt online updates lokal synchronisieren möchtest, müssen zu erst die Updates runtergeladen werden. Das geht mittels "git fetch [remote]". Wenn du keinen remote angibst wird origin geupdated. Die änderungen müssen danach gemerged werden mittels "git merge origin/master" (oder ein anderer Branch Name, wenn du auf einem anderen Branch bist). Allerdings bietet git dafür eine einheitliche funktion die bereits beides macht: "git pull". Das führt zu erst ein fetch aus, und danach ein merge auf den aktuellen Branch. Während pull das ist was man meist machen will, wenn mehrere Leute an einem projekt Arbeiten, und du lokale änderungen machst, willst du vielleicht zu erst schauen ob es konflikte geben kann, bevor der merge ausgeführt wird, da das sonst echt hässlich werden kann. Dann sollte man zunächst ein "git fetch" machen, und dann per hand mergen:
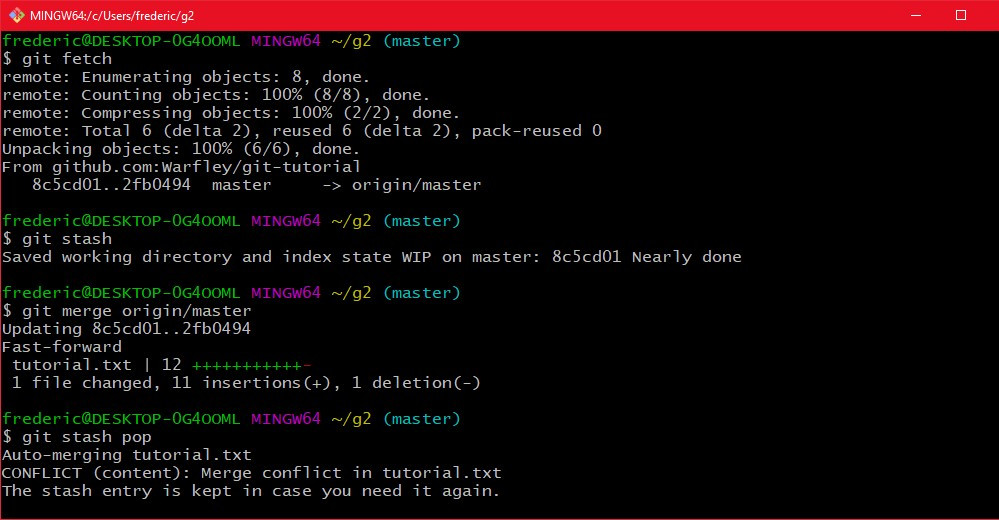
Hier kann ich am git fetch sehen das master geupdated wurde. Da ich aktuell auf master ein paar Änderungen mache will ich nicht direkt mergen, sondern mache zu erst ein stash, um meine Arbeitskopie zu sichern. Dann mach ich den merge gegen origin, um dann mit dem git stash pop meine neuen Änderungen reinzubringen. Git stash hat den Vorteil, das wenn es Konflikte gab die Änderungen immernoch im Stash bleiben, es geht also nix verloren. Ich kann dann einfach einen neuen Branch erzeugen, und dort den stash popen um dann auf dem neuen Branch weiter zu machen.
Um meine Lokalen änderungen zu verwerfen könnte ich jetzt einfach "git reset --hard origin/master" statt git merge machen, wenn ich mir sicher bin das ich die lokalen Änderungen nicht mehr brauche.
So... Das waren die absoluten Grundlagen von Git. Ursprünglich wollte ich ein vollständiges Tutorial machen, also mit so sachen wie Rebase, Konfliktresolution, History rewrite, LFS, Pull Requests, etc., aber wenn ich mir die bisherige Länge ansehe, soll das vorerst reichen. Fall interresse besteht, fragt einfach, ich würde auch einen Zweiten Teil schreiben. Zu guter letzt kommen jetzt noch ein paar tipps zu git.
Git ist für Source versionierung gemacht. Git mag binäre dateien überhaupt nicht und vor allem große Binäre datien können Git komplett lahmlegen. Der Grund dafür ist das git statt diff's (wie SVN) die unterschiedlichen Dateien einfach in ihrer gesamtheit, dafür Komprimiert speichert. Die Komprimierung ist beschissen für Binäre Dateien, was das clonen von Repositories mit Binären dateien extrem langsam werden lässt. Dafür gibt es aber git-lfs, was sich darum kümmert.
Damit zusammen hängt auch, man möchte einige sachen einfach nicht in sein git Repositroy commiten. Dazu gehören executeables, DLL's, etc.. Damit man nicht ausversehen bei einem "git add -A" die dateien trozdem reinkommen, gibt es dafür die .gitignore. Das ist einfach eine Datei die git sagt, welche Dateien nicht beachtet/ignoriert werden sollen. Es gibt auf GitHub ein Repository von GitHub selbst, was gitignroes für die meißten größeren IDE's und Pragrammiersprachen hat Link. Einfach im Projektverzeichnis eine neue Textdatei .gitignore anlegen und dort die Dateien reinschreiben die ignoriert werden sollen, bzw. einfach den Inhalt einer der Vorgefertigten gitignores reinkopieren.
Ein weiterer Punkt ist SSH URLS. Git kann sowohl HTTPS als auch SSH als protokolle zum synchronisieren mit dem Server. HTTPS benötigt Passworteingabe bei jedem Fetch/Pull und Push. Außerdem sind Passwörter nicht unbedingt die sicherste Lösung. Daher kann man SSH nehmen, wofür man dann einen Private und Public Key braucht. Mehr dazu gibt es hier
Wenn man nicht auf online Services wie GitHub oder GitLab zurückgreifen will, aber trozdem ein Backup mit so einem tollen Webinterface haben möchte, kann auf einem eigenen Server (oder Raspberry pi lokal) eine eigene GitLab instanz oder, wenn man eher ein Fan vom GitHub layout ist, Gitea instanz hosten. Gitlab braucht ne menge Resourcen (Unter 8 GB RAM würd ichs nicht versuchen), aber Gitea läuft super auch auf der schwächsten Hardware, und erlaubt problemlos das Hosten auch auf Hardware wie dem Raspberry pi. Natürlich sollte man sich dann ein etwas sichereres Medium als eine SD Karte besorgen, ist aber ne Kostengünstige Option wenn man seinen Code nicht auf fremden Servern hosten möchte.
Hier ist mal eine etwas erweiterte Erklärung für Git, denn mMn. kann man Git nicht richtig verwenden wenn man es nicht richtig verstanden hat und im gegensatz zu SVN ist Git deutlich komplizierter. Das sollte einen aber nicht Abschrecken, denn wenn mans einmal verstanden hat ist alles ganz einfach. Außerdem hat Git die Versionskontrollkriege gewonnen, also ob mans mag oder nicht, drum rum kommt man eh kaum.
Git basiert auf einem Graphen. Die Knoten des Graphen sind so genannte Commits. Diese bezeichnen Momentaufnahmen (Snapshots) des aktuellen Code Status und bestehen im wesentlichen aus drei Dingen:
1. Allen Vorgänger-Commits auf denen es aufbaut, welche die Kanten im Graphen darstellen
2. Meta Informationen, wer den Commit verfasst hat (Name, E-Mail), wann der Commit getätigt wurde sowie eine kleine Nachricht (Message) was der Commit denn macht
3. Die Code Änderungen zu den Vorgängern
Über diese 3 Sachen wird dann ein Hash gebildet, über den jeder Commit eindeutig identifiziert werden kann.
Ein kleines Beispiel, ich arbeite an einem Git Projekt und habe grade eine Funktion hinzugefügt. Dann würde ich einen neuen Commit erstellen, welcher diese Funktion enthält, eine Message wie "Adding Function XXX" zusammen mit meinem Namen, den aktuellen Datum und einer Referenz was die Version war mit der ich angefangen habe.
Die Commits die sich gegenseitig Verlinken (da jeder Commit einen Verweis auf den vorrigen Commit enthält) bilden damit den oben erwähnten Graphen. Ein Git repository speichert nun diesen Graphen und stellt eine akutelle Arbeitsversion, den Working Tree, bereit. Der Working Tree basiert dabei auf einem Commit, der wird HEAD genannt, also der aktuelle Commit den wir betrachten. Wenn wir einen neuen Commit hinzufügen, wird der aktuelle HEAD als Vorgänger in dem Commit vermerkt.
Während Git zwar jeden Commit einzeln über einen Hash addressieren kann, arbeitet man für gewöhnlich auf so genannten Branchen. Ein Branch ist eine Serie an Commits der man praktisch einen Namen gibt. Der Branch selbst bezeichnet dann praktisch den letzen Commit in der Serie. Der Standard-Branch ist der "master" Branch, den es in jedem Repository gibt.
Doch mal zum praktischen Teil. Wenn man Git installiert hat (https://git-scm.com/), kann man das git programm einfach über die Kommandozeile bedienen (für Windows wird eine eigene "Git-Bash" mitgeliefert, die die grundlegenden Unix-Shell funktionen zur Verfügung stellt). Sagen wir mal wir haben ein Projekt in einem Ordner, so müssen wir erst mal ein Git Repository dafür in diesem Ordner erstellen. Dafür navigieren wir unsere Shell in den Projektordner und rufen "git init" auf:
Das Kommando "git status" berichtet über den aktuellen Status des Git repositories. In dem Bild oben können wir sehen, dass zunächst einmal der master Branch erzeugt wurde, dieser branch aber noch keinen Commit enthält. Außerdem sagt git uns das es die Datei tutorial.txt, an der ich grade schreibe, in dem Ordner gibt, allerdings diese nicht im git repository hinzugefügt ist, also "untracked" (Änderungen werden nicht verfolgt) ist. Das wollen wir schnell mal ändern, und fügen einen ersten Commit hinzu, mit dem Inhalt den ich bis jetzt geschrieben habe.
Dafür müssen wir git zunächst einmal sagen welche dateien wir denn Commiten wollen. Das geht über "git add Dateiname1 [Dateiname2 [...]]" (für die Leute die ungewohnt mit der typischen schreibweise für Kommandozeilen Manuals sind, was in "[" und "]" steht ist optional, oben das bedeutet also das man beliebig viele Dateinamen angeben kann). Wenn man alle Dateien hinzufügen möchte die als untracked gekennzeichnet sind (im git status), kann man einfach "git add -A" verwenden. In meinem Fall führe ich also jetzt "git add tutorial.txt" aus:
Das "git status" sagt uns nun das eine änderung zum Commit vorgemerkt wurde, die erstellung der datei tutorial.txt (außerdem erkennt git den Screenshot von oben als neue Datei, den will ich aber nicht commiten). Diese vorgemerkten Änderungen nennt man stage. Das wichtige dabei ist, es wird die Datei so vorgemerkt wie zu dem Zeitpunkt des "git add". Die Änderungen die ich seit dem gemacht hab sind da nicht drin, wie ein weiteres "git status" nach ein paar Änderungen zeigt:
Der nächste Schritt ist das Erstellen des eigentlichen commits. Doch bevor wir commiten können, müssen wir git erst einmal sagen wer wir sind. Das geht via "git config".
Code: Alles auswählen
$> git config --global user.name "Vorname Nachname"
$> git config --global user.email "email@addr.de"Nachdem wir git gesagt haben wer wir sind, können wir nun mit "git commit" commiten. Wenn man git commit ohne weitere Argumente aufruft, öffnet sich der für Git eingestellte Editor (Vim oder Nano standardmäßig) um eine Commit Nachricht einzutragen:
Als Nachricht habe ich "Initial Commit" gewählt, da das die standardmäßige Nachricht ist die bekannte Git plattformen wie GitHub oder GitLab für neue repositories immer wählen. Zeilen die mit einem "#" anfangen sind auskommentiert, und werden nicht als Commit Message betrachtet. Diese geben nochmal grundlegend die Zusammenfassung die einem git status anzeigt. Dann speichert und schließt man den Editor einfach. Wenn man den Commit abbrechen will, schreibt man einfach nichts rein (also eine Leere Commit Message/nur kommentare drin) und speichert und schließt den Editor (z.B. wenn man bei der Zusammenfassung in den Kommentaren merkt das man was commited was eigentlich nicht commited werden soll, wie Debug Code).
Der "git commit" Befehl kann noch einige Argumente nehmen. "git commit -a" z.B. staged automatisch alle modifikationen in getrackted files (also alles was im "git status" unter "changes not staged for commit" fällt, nicht die "untracked files") vor dem Commit, kann also alle Änderungen gleich mit commiten, ohne das man ein "git add" vorher machen muss. Außerdem gibt es noch die -m Option, mit der man direkt die Commit Message übergeben kann, also z.B. "git commit -m "Initial Commit". Davon würde ich aber strikt abraten aus zwei Gründen. Zum einen fehlt einem die Übersicht im Commit Editor (über was commited wird, was untracked ist, etc.), sowie die möglichkeit abzubrechen, wenn man das nicht Commiten möchte. Grade zusammen mit der -a Option, kann es sehr leicht passieren das man außversehen Debug Code o.ä. mit Commited den man eigentlich draußen lassen würde, und ein schnelles drüberschauen über die Kommentare im Editor kann einem aufwändiges zurücksetzen im Nachinein ersparen. Zum anderen haben Plattformen wie GitHub oder GitLab syntaktische hervorhebung für Code über "``". D.h. wenn man einen Ausdruck als Code markieren will, setzt man den in ``, z.B. wenn man eine Funktion hinzufügt könnte die Message so aussehen: "Adding Function `FunctionThatDoesSomeStuff`", um klarzustellen das der Funktionsnamen im Source FunctionThatDoesSomeStuff ist. Das Problem ist nun das `` in Bash einen Befehl kennzeichnen der Ausgeführt werden soll. Wenn man also z.b. sowas schreibt: git commit -m "Adding description for `rm -rf /`" hat man schwup die wupp sein gesammtes Linux system gelöscht, da die Bash dumm wie sie ist, einfach "rm -rf /" ausführt. Daher empfehle ich nicht -m zu benutzen.
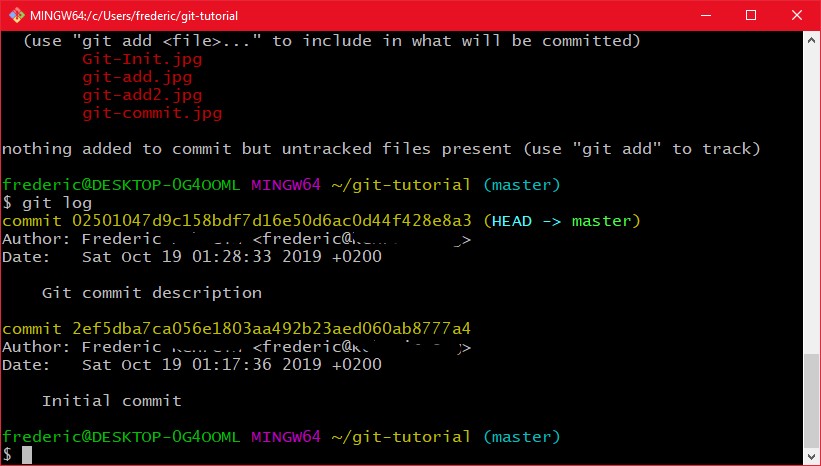
Jetzt nach meinem Commit habe ich ein gutes Stück weiter an diesem Tutorial gearbeitet, und würde gerne die neuen Änderungen commiten. Das geht jetzt ganz einfach über "git commit -a" wie oben beschrieben. Nun möchte ich meine bisherigen 2 Commits sehen. Dafür gibt es den Befehl "git log" (da ich nicht möchte das irgendwer der diesen Beitrag findet mir einfach so Mails schickt habe ich meine E-Mail addresse zensiert):
Das log zeigt die Commits, sortiert nach der Reihenfolge im Graphen, mit der Message, Datum, Committer Name und E-Mail, sowie eindeutigem Hash an. Außerdem markiert uns git log noch welche Branches auf welche Commits zeigen. In meinem Fall ist master = HEAD und sie zeigen auf den neusten Commit den ich grade gemacht hab.
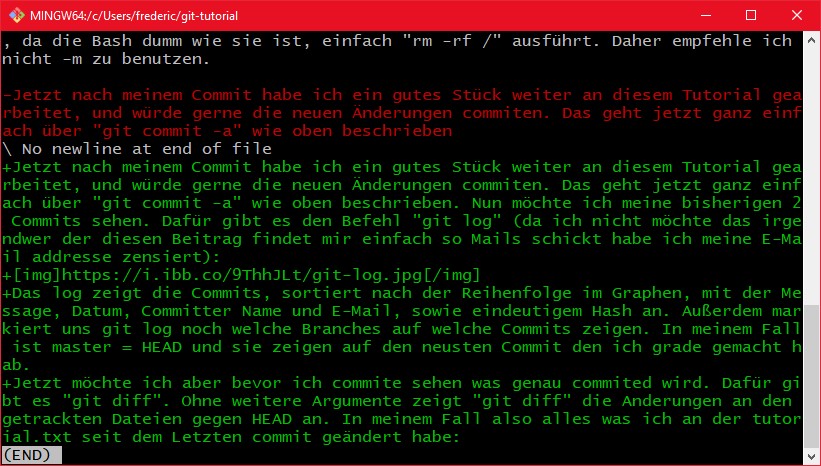
Jetzt möchte ich aber bevor ich commite sehen was genau commited wird. Dafür gibt es "git diff". Ohne weitere Argumente zeigt "git diff" die Anderungen an den getrackten Dateien gegen HEAD an. In meinem Fall also alles was ich an der tutorial.txt seit dem Letzten commit geändert habe:
Das rote sind die Zeilen die gelöscht wurden, das grüne die Zeilen die hinzugefügt wurden, und das graue die Zeilen die gleich geblieben sind. Das diff basiert dabei auf Zeilenbasis, eine änderung in einem Wort, führt also dazu das diese Zeile in der alten Fassung gelöscht wurde (also rot erscheint) und in der neuen Fassung direkt drunter hinzugefügt wurde (also in grün).
Ich kann mir aber auch die unterschiede zu einzelnen Commits anzeigen lassen "git log 2ef5dba7c" zeigt mir z.B. die unterschiede zwischen meiner akutellen Arbeitskopie und dem Initialen Commit 2ef5dba7ca056e1803aa492b23aed060ab8777a4 (kann für die Befehle abgekürzt werden auf die ersten paar zeichen des Hashs) an. Die Unterschiede zwischen zwei Commits lassen sich via "git diff commitID1 commitID2" anzeigen lassen, wobei das git diff die änderungen von Commit1 zu Commit2 anzeigt (wenn man also die beiden vertauscht ist das was vorher rot war grün und anders rum, da die änderungen praktisch dann die Rückgänigmachung wären).
Man kann Commits auch relativ zu anderen Commits identifizieren. Dafür kann man über ~ in der Historie zurückgehen. "02501047d9~1" bezeichnet damit den ersten commit vor "02501047d9". "git diff 02501047d9~1 02501047d9" zeigt also die unterschiede an die der Commit 02501047d9 hinzugefügt hat (also die unterschiede Zwischen dem Initial Commit und dem zweiten Commit). Außerdem können Commits auch über Branch Namen angesprochen werden. "git diff HEAD~2" gibt mir also die änderungen der letzten 2 commits zurück.
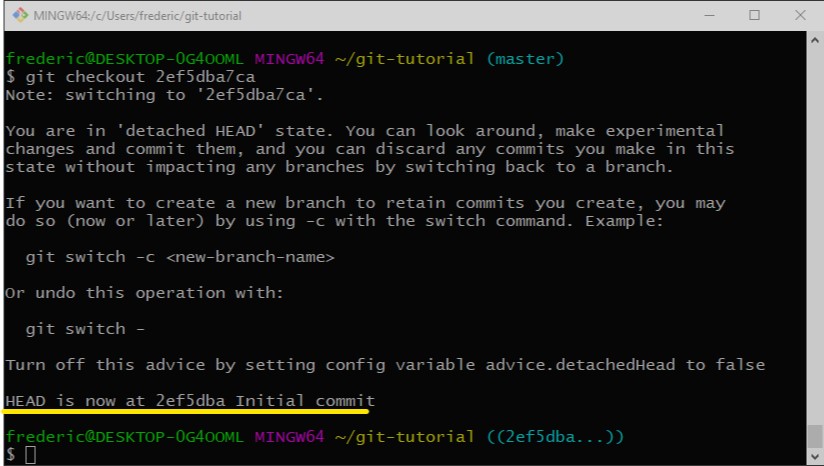
Nun, da wir wissen wie wir Commits erstellen, uns die Historie anschauen und Änderungen im Detail betrachten können, kommen wir zu den etwas komplexeren Themen. Sagen wir mal wir haben in unserer Software einen Bug festgestellt der vorher noch nicht da war, und wollen feststellen wann dieser dazu kam, du möchtest also zurück zu einer älteren Version gehen. Das geht über "git checkout" Wenn wir unser Repository als Graph betrachten, so ist unser aktuelles Arbeitsverzeichnis eine Instanz einer Commits. Der Commit den wir uns aktuell betrachten wird über den HEAD markiert. Wenn wir jetzt also ein "git checkout" machen wird der HEAD auf einen anderen Commit gesetzt, und damit dieser Commit in unser Arbeitsverzeichnis geschrieben. Für dieses Beispiel checken wir doch einfach mal den "Initial Commit" aus
Zunächst einmal gibt uns Git hier ne ganze Menge text. Der Grund dafür ist, das nun unser HEAD auf einen Commit zeigt, und nicht mehr Teil eines Branches ist. Der Commit liegt zwar auf dem "master" branch, aber wir sind dennoch jetzt im detached HEAD mode, was heißt, das jeder Commit den wir jetzt machen würden, zu keinem Branch hinzugefügt werden würde. Wenn wir also was anderes auschecken, gibt es keinen Branch, und damit keinen Namen, mit dem wir den Commit wieder finden würden, und damit ist dieser Commit verloren. Wir haben keine Möglichkeit den wieder zu finden, daher sagt uns diese Nachricht wie wir in solchen Fällen agieren können.
Die letzte Zeile, die ich markiert habe, sagt uns nun das wir den Commit 2ef5dba Initial Commit wiederhergestellt haben, und unser Arbeitsverzeichnis in dem Zustand dieses Commits ist. Jetzt könnten wir z.B. unsere Anwendung testen, ob der Bug immernoch vorkommt. Und wenn wir damit fertig sind, und auf dem "master" Branch weiterarbeiten wollen, müssen wir den wieder Auschecken mittels "git checkout master".
Wenn man nur einzelne Dateien zurücksetzen möchte, geht das über "git checkout -- PFADE". z.B. "git checkout HEAD~1 -- tutorial.txt" würde die tutorial.txt auf die version vor dem letzten Commit zurücksetzen. Das ist oft Hilfreich wenn man änderungen die man gemacht hat verwefen will, einfach "git checkout HEAD -- pfad/zu/einer/Datei" eintippen und die Datei pfad/zu/einer/Datei wird dann wieder auf den Zustand des letzten Commits zurückgesetzt.
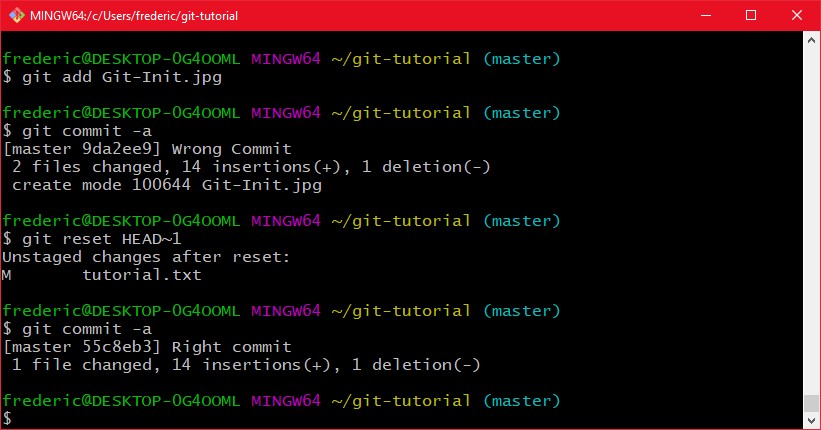
Es kommt öfter als man möchte vor, das man etwas commited hat was man nicht möchte, oder einfach einen Commit komplett löschen will. Dafür gibt es den befehl "git reset COMMIT". Dieser setzt den aktuellen Branch auf einen neuen Commit. Man unterscheidet hierbei zwischen Soft- und Hard-Reset. Bei einem Soft Reset wird der Commit zwar vom Branch entfernt, aber die Änderungen bleiben lokal erhalten. Sagen wir mal du hast eine Datei commited die du eigentlich nicht drin haben willst und merkst das erst nach dem Commit z.B. habe ich jetzt die Git-Init.jpg commited und sehe das dann an der Nachricht beim git commit. Dann kann ich einfach mittels soft reset das ganze zurücksetzen und nochmal neu, richtig commiten, ohne irgendwelche daten zu verlieren:
Der Hard Reset resettet auch das Arbeitsverzeichnis, und löscht die Änderungen damit permanent. Damit sollte man sehr vorsichtig sein. Den macht man mit "git reset --hard COMMIT".
Es kommt öfter mal vor das man vor einem "git checkout" oder "git reset" bereits einige änderungen an seinem Code gemacht hat, die aber noch nicht soweit sind das man einen eigenen Commit dafür machen will. Um solche änderungen zwischen zu speichern, bevor man eventuell größere Änderungen an dem Repository vornimmt, kann man diese änderungen im stash zwischenspeichern. Der stash ist ein Stack von Arbeitsänderungen. Ich kann auf den stash pushen, mit "git stash push" oder kurz "git stash", und den letzten Stash mit "git stash pop" wiederherstellen. Wenn ich also jetzt in der Commit historie zurückgehen will, ohne einen neuen commit zu machen, würde ich meine änderungen zu erst Stashen, dann den checkout machen, und dann wieder unstashen:
Eine weitere schöne eigenschaft von git stash ist, wenn ich z.B. grade ein Feature entwickle und plötzlich ein Bug auftritt, kann ich meine änderungen einfach stashen, schauen ob sie durch die aktuellen Änderungen kamen und wenn ja, kann ich den stash wieder popen und die Fehlerquelle suchen. Mit -- kann man auch einfach einzelne Dateien stashen:
Code: Alles auswählen
$> git stash push -- tutorial.txt
...
$> git stash popUm einen branch zu erzeugen kann man "git checkout -b branchName" verwenden, das erzeugt einen Branch und wechselt direkt zu diesem. Sagen wir mal ich hätte jetzt einen Korrekturleser, der dieses Tutorial gegen ließt und einige rechtschreibfehler korrigieren möchte:
Hier wird ein neuer Branch corrections erstellt, auf dem dann ein neuer Commit mit Typo Fixes erstellt wird. Im git Log ist dann zu sehen das sich dieser branch um einen Commit von master unterscheidet.
Wenn ich nun diese Änderungen auf master übernehmen will mache ich einen so genannten merge, mit "git merge":
Dafür gehe ich zu erst wieder auf den master branch (in den ich ja reinmergen möchte), und sage dann "git merge corrections". Jetzt übernimmt git automatisch die Änderungen vom branch corrections und wendet sie auf master an. Den branch corrections kann ich dann nach dem merge mittels "git branch -D corrections" löschen.
Wenn es bei einem Merge zu einem Konflikt kommt, z.B. wurde auf dem master branch weiteres bearbeitet, wovon corrections nichts weiß, so versucht git diese beim merge automatisch aufzulösen. Wenn das schief geht muss man das per hand machen. Das geht aber für dieses Tutorial zu weit, da dieses Tutorial vorerst nur an Leute gerichtet ist die alleine git verwenden und das eher ein Team problem ist.
Wenn man mehrere Branches hat, kann man die sachen die oben mit commits gemacht wurden natürlich auch mit branches machen. So kann man z.B. master auf den aktuellen commit von corrections setzen via "git reset [--hard] corrections".
Zum Schluss möchte ich noch kurz auf Online Repositories zu sprechen kommen. Ob man nun git verwendet um seinen Code auf GitHub o.ä. zu veröffentlichen, oder einfach ein online Backup haben möchte, so muss man sein git Repository mit einem Online Repository, einem so genannten Remote, verbinden.
Wenn man z.B. auf GitHub ein Repository hat, ein frisch erstelltes, oder ein bereits bestehendes, so findet man (meist irgendwo oben auf der Startseite des Repos) eine "clone URL". Diese gibt es für SSH oder HTTPS, zwei protokolle die git kann. Auf die beiden Methoden werde ich später nochmal genauer eingehen. Zunächst einmal arbeiten wir aber mit der HTTPS URL.
Gehen wir jetzt erst mal von dem Fall aus das wir unser Repository auf GitHub hochladen wollen. Dann erstellen wir zunächst einmal ein Leeres Repository auf GitHub (wichtig, weder ReadMe noch gitignore erzeugen lassen)
Da sehen wir dann auch schon kurze Erklärung wie es weiter geht. Oben finden wir unsere clone URL https://github.com/Nutzername/ReposName.git. Nun fügen wir diese als remote zu unserem repository hinzu via "git remote add origin URL". Damit können wir jetzt immer origin statt der URL schreiben.
Nun müssen wir unseren master branch nur noch auf den server hochladen. Um das Lokale repository auf den server hochzuladen gibt es das Kommando "git push". Bei der ersten benutzung müssen wir git aber noch sagen welcher remote branch dem aktuellen branch entsprechen soll, wir müssen also in git sprech den lokalen branch einen remote branch tracken lassen.
Der push befehl gibt uns dann ein bisschen was an Text zurück, über den Status des Hochladens. Da wir HTTPS benutzen werden wir bei jedem Push nach einem Passwort gefragt, das müssen wir dann eingeben.
Die letzte Zeile in der push ausgabe sagt uns dann das der branch master nun origin master folgt (trackt) und damit benötigen wir für folgende pushs jetzt nicht mehr das "--set-upstream ..." Wenn wir jetzt lokal weiter gearbeitet haben, ein paar commits gemacht haben, und die am ende des Tages zum Backup hochladen wollen, machen wir nur noch ein "git push" und alles ist synchronisiert
Wenn man GitLab benutzt muss man nicht vorher ein Repo erstellen, "git push --set-upstream URL master" erzeugt automatisch ein repository mit dem Namen der in der URL angegeben wird, solang die URL die typische GitLab URL form hat.
Wenn wir nun auf einem Zweiten rechner das git Repository runterladen wollen, können wir das über "git clone URL [ordner]" machen. Wenn ein (Ziel-)Ordner angegeben wird, dann wird der Ordner mit diesem Namen erstellt und da rein geklont, ansonsten wird ein neuer Ordner mit dem Namen des Repositories erstellt. Das git clone erzeugt direkt den lokalen master branch und trackt den gegen origin/master.
Die serverseitigen sachen werden praktisch als eigene Branches von git gehandhabt. Der Branch "master" der im online repo origin liegt, wird mit origin/master addressiert. Wenn du also die Änderungen deines Lokalen branches mit dem Server vergleichen willst kannst du das via "git diff origin/master" machen:
Generell kannst du origin/branch genauso verwenden wie Commit Hashs, nicht wie branches. D.h. wenn du z.b. "git checkout origin/master" machst landest du wieder im detached HEAD mode, und befindest dich praktisch auf keinem branch.
Wenn du jetzt online updates lokal synchronisieren möchtest, müssen zu erst die Updates runtergeladen werden. Das geht mittels "git fetch [remote]". Wenn du keinen remote angibst wird origin geupdated. Die änderungen müssen danach gemerged werden mittels "git merge origin/master" (oder ein anderer Branch Name, wenn du auf einem anderen Branch bist). Allerdings bietet git dafür eine einheitliche funktion die bereits beides macht: "git pull". Das führt zu erst ein fetch aus, und danach ein merge auf den aktuellen Branch. Während pull das ist was man meist machen will, wenn mehrere Leute an einem projekt Arbeiten, und du lokale änderungen machst, willst du vielleicht zu erst schauen ob es konflikte geben kann, bevor der merge ausgeführt wird, da das sonst echt hässlich werden kann. Dann sollte man zunächst ein "git fetch" machen, und dann per hand mergen:
Hier kann ich am git fetch sehen das master geupdated wurde. Da ich aktuell auf master ein paar Änderungen mache will ich nicht direkt mergen, sondern mache zu erst ein stash, um meine Arbeitskopie zu sichern. Dann mach ich den merge gegen origin, um dann mit dem git stash pop meine neuen Änderungen reinzubringen. Git stash hat den Vorteil, das wenn es Konflikte gab die Änderungen immernoch im Stash bleiben, es geht also nix verloren. Ich kann dann einfach einen neuen Branch erzeugen, und dort den stash popen um dann auf dem neuen Branch weiter zu machen.
Um meine Lokalen änderungen zu verwerfen könnte ich jetzt einfach "git reset --hard origin/master" statt git merge machen, wenn ich mir sicher bin das ich die lokalen Änderungen nicht mehr brauche.
So... Das waren die absoluten Grundlagen von Git. Ursprünglich wollte ich ein vollständiges Tutorial machen, also mit so sachen wie Rebase, Konfliktresolution, History rewrite, LFS, Pull Requests, etc., aber wenn ich mir die bisherige Länge ansehe, soll das vorerst reichen. Fall interresse besteht, fragt einfach, ich würde auch einen Zweiten Teil schreiben. Zu guter letzt kommen jetzt noch ein paar tipps zu git.
Git ist für Source versionierung gemacht. Git mag binäre dateien überhaupt nicht und vor allem große Binäre datien können Git komplett lahmlegen. Der Grund dafür ist das git statt diff's (wie SVN) die unterschiedlichen Dateien einfach in ihrer gesamtheit, dafür Komprimiert speichert. Die Komprimierung ist beschissen für Binäre Dateien, was das clonen von Repositories mit Binären dateien extrem langsam werden lässt. Dafür gibt es aber git-lfs, was sich darum kümmert.
Damit zusammen hängt auch, man möchte einige sachen einfach nicht in sein git Repositroy commiten. Dazu gehören executeables, DLL's, etc.. Damit man nicht ausversehen bei einem "git add -A" die dateien trozdem reinkommen, gibt es dafür die .gitignore. Das ist einfach eine Datei die git sagt, welche Dateien nicht beachtet/ignoriert werden sollen. Es gibt auf GitHub ein Repository von GitHub selbst, was gitignroes für die meißten größeren IDE's und Pragrammiersprachen hat Link. Einfach im Projektverzeichnis eine neue Textdatei .gitignore anlegen und dort die Dateien reinschreiben die ignoriert werden sollen, bzw. einfach den Inhalt einer der Vorgefertigten gitignores reinkopieren.
Ein weiterer Punkt ist SSH URLS. Git kann sowohl HTTPS als auch SSH als protokolle zum synchronisieren mit dem Server. HTTPS benötigt Passworteingabe bei jedem Fetch/Pull und Push. Außerdem sind Passwörter nicht unbedingt die sicherste Lösung. Daher kann man SSH nehmen, wofür man dann einen Private und Public Key braucht. Mehr dazu gibt es hier
Wenn man nicht auf online Services wie GitHub oder GitLab zurückgreifen will, aber trozdem ein Backup mit so einem tollen Webinterface haben möchte, kann auf einem eigenen Server (oder Raspberry pi lokal) eine eigene GitLab instanz oder, wenn man eher ein Fan vom GitHub layout ist, Gitea instanz hosten. Gitlab braucht ne menge Resourcen (Unter 8 GB RAM würd ichs nicht versuchen), aber Gitea läuft super auch auf der schwächsten Hardware, und erlaubt problemlos das Hosten auch auf Hardware wie dem Raspberry pi. Natürlich sollte man sich dann ein etwas sichereres Medium als eine SD Karte besorgen, ist aber ne Kostengünstige Option wenn man seinen Code nicht auf fremden Servern hosten möchte.
-
kralle
- Lazarusforum e. V.
- Beiträge: 1383
- Registriert: Mi 17. Mär 2010, 14:50
- OS, Lazarus, FPC: Manjaro Linux, Mint und Windows 10 ,Lazarus 4.99, FPC-Version: 3.3.1
- CPU-Target: 64Bit
- Wohnort: Bremerhaven
- Kontaktdaten:
Re: GIT für Lazarus-Projekte
Moin,
@socke: Das mit dem "bare"-Repo verstehe ich noch nicht, aber das kommt bestimmt noch.
@Warf: Puh, da hat sich aber einer Mühe gegeben. Danke.
So viele Infos am frühen Samstag Morgen zu lesen, war der Hammer.
Ich werde das die Tage versuchen StepByStep nachzuvollziehen und werde dann das Ergebnis und/oder Fragen hier wieder posten.
Gruß HEiko
@socke: Das mit dem "bare"-Repo verstehe ich noch nicht, aber das kommt bestimmt noch.
@Warf: Puh, da hat sich aber einer Mühe gegeben. Danke.
So viele Infos am frühen Samstag Morgen zu lesen, war der Hammer.
Ich werde das die Tage versuchen StepByStep nachzuvollziehen und werde dann das Ergebnis und/oder Fragen hier wieder posten.
Gruß HEiko
OS: MX Linux, Linux Mint und Windows 11
FPC-Version: 3.3.1 , Lazarus 3.99
+ Delphi XE7SP1
FPC-Version: 3.3.1 , Lazarus 3.99
+ Delphi XE7SP1
-
fliegermichl
- Lazarusforum e. V.
- Beiträge: 1805
- Registriert: Do 9. Jun 2011, 09:42
- OS, Lazarus, FPC: Lazarus Fixes FPC Stable
- CPU-Target: 32/64Bit
- Wohnort: Echzell
Re: GIT für Lazarus-Projekte
Ich hab da ein ziemlich gutes Tutorial gefunden, welches die wichtigsten Dinge verständlich beschreibt.
http://www-cs-students.stanford.edu/~bl ... /ch02.html
http://www-cs-students.stanford.edu/~bl ... /ch02.html